
PACE: The research that sparked a patient rebellion and challenged medicine

Editor’s Notes: The anonymized data from the PACE trial was released following our publication, resulting in additional discussion of the trial outcomes. The preliminary findings from these new analyses can be found here on “improvement” and on “recovery”.
This article was updated on March 25, 2016, as an earlier version had been posted in error on March 24, 2016. You will see two new sections: Overall impact of these changes, and PACE author explanations, in this version. We regret and apologize for the mistake. Thank you.
Update March 28: Language in the physical function section about scores for the British working-age population has been changed to be more precise.
Update March 26: After reader feedback, the section “The ME/CFS criteria for recovery” has been rewritten for clarity. There has also been a change to footnote [5].
A brief editorial with the main points from the below analysis can be found here.
In 2011, researchers announced that PACE, the largest treatment trial in the history of chronic fatigue syndrome, had been a great success. That seemed like great news since there is no known cure for this devastating disease that affects over a million people in the United States alone, including Laura Hillenbrand, the best-selling author of Seabiscuit, and jazz pianist Keith Jarrett. Exercise and psychotherapy, the researchers said, can significantly improve and sometimes cure chronic fatigue syndrome (CFS), which is also sometimes called myalgic encephalomyelitis (ME). Headlines announced the study finding around the world; it was simple, as The Independent wrote, “Got ME? Just get out and exercise, say scientists.”
The finding struck many ME/CFS sufferers as preposterous—and their concerns about the way the trial was designed and conducted, after long being dismissed, were suddenly supported in a recent investigative tour de force by David Tuller, academic coordinator of UC Berkeley’s joint masters program in public health and journalism. In response to his investigation, six scientists from Stanford, Columbia, and elsewhere sent an open letter to the editor of The Lancet demanding a fully independent investigation into the trial. After three months with no response from The Lancet, the letter was republished with 42 signatures. After that, The Lancet editor, Richard Horton, emerged from witness protection and invited the group to submit a letter about the concerns for publication. The study is under increasing scrutiny by scientists and science writers about whether its conclusions are valid.
The question of how all this happened and how the criticism is being handled have sent shockwaves through medicine. The results from PACE (including these) have been published in prestigious journals and influenced public health recommendations around the world; and yet, unraveling this design and the characterization of the outcomes of the trial has left many people, including me, unsure this study has any scientific merit. How did the study go unchallenged for five years? And how could journalists have recognized the problems before reporting unqualified, but unjustified, good news?
There were problems with the study on almost all levels, but our goal in this piece is to examine a critical issue that is increasingly being talked about in academic research but less so in the news media, due to its complexity: study design.
What the researchers did, their claimed results, and the study’s impact
Precisely what symptoms characterize chronic fatigue syndrome (CFS) is a matter of dispute, as there are many different definitions in use. All agree that the illness includes prolonged and debilitating fatigue, and most require additional symptoms, for example problems with cognition, blood pressure regulation, and sleep. Most researchers in the field consider the hallmark symptom of the disease to not be fatigue at all but instead an exacerbation of all these symptoms following exercise, called post-exertional malaise. The term myalgic encephalomyelitis (ME) is sometimes used as a synonym for CFS and other times reserved for more severely ill patients.
Researchers at a prestigious set of British medical institutions,[1] many of whom had long been proponents of exercise and psychotherapy as treatments for chronic fatigue syndrome, designed PACE as a randomized trial to test these treatments. In particular, they studied four interventions used to treat the illness:
- Specialist medical care (SMC) alone
Patients visited a doctor and received standard symptomatic treatment, including sleep and pain medication. - Graded Exercise Therapy (GET)
Patients were put on an exercise program starting at a level that patients could do on their worst days and slowly increasing in duration and intensity. Patients were encouraged to continue their exercise even if it exacerbated symptoms. In addition, patients received specialist medical care. - Cognitive Behavioral Therapy (CBT)
Patients were given psychotherapy based on the idea that their illness was being perpetuated by their false belief that they had a physiological illness that caused exercise to harm them. Therapists gently confronted these “unhelpful cognitions” and encouraged patients to think about their symptoms less and to gradually increase their exercise. In addition, patients received specialist medical care. - Adaptive Pacing Therapy (APT)
Patients independently developed a self-help method they call “pacing,” in which they carefully monitor their energy levels from day to day and aim to stay within them. The researchers developed a program, which, they argued, encapsulated this, and was designed to balance rest and activity in order to avoid exacerbations of fatigue and other symptoms. In addition, patients received specialist medical care.
PACE was a randomized, controlled trial, the gold standard of medical research, meant to provide the research community with a rock-solid conclusion about which of these four treatments worked best. In this type of trial, one assigns patients randomly to different groups and then applies different treatments to the groups. A “control” group generally receives standard or no treatment (in this case, specialist medical care only), while an “experimental” group receives the new treatment or treatments under investigation (in this case, three treatments were compared).
The progress of the groups is analyzed statistically. If patients in one of the experimental groups improve more than the control group, statistics can tell us the likelihood that the difference would have occurred assuming the treatment assignment had no impact.
If the probability is low, one has evidence that the treatment for the experimental group may have had an impact, compared to that for the control. In the PACE trial, the groups were first compared on the basis of how much they improved, and then second, on how many patients achieved “recovery” in each group.
The researchers studied 641 patients from 2005-2010 in England and Scotland at a cost of $8 million. They followed patients who met entry criteria for 52 weeks, assessing their progress both through patient’s self-assessments of their improvement and through objective measurements.
The researchers reported that cognitive behavioral therapy and graded exercise therapy resulted in reduced fatigue and increased physical function compared with specialist medical care alone or with adaptive pacing therapy. And, in a follow-up study, they said that 22 percent of patients in cognitive behavior therapy or graded exercise therapy (plus treatment by a doctor) met “recovery criteria”, compared to only 7 to 8 percent of patients in the other groups.
These results were covered in the news media, for the most part, uncritically:
“Psychotherapy Eases Chronic Fatigue Syndrome, Study Finds”—New York Times
“Pushing limits can help chronic fatigue patients”—Reuters
“Brain and body training treats ME, UK study says”—BBC
“Therapy, Exercise Help Chronic Fatigue Syndrome”—WebMD
“Helping chronic fatigue patients over fears eases symptoms”—Fox News
“Chronic fatigue syndrome patients’ fear of exercise can hinder treatment – study”— The Guardian
“Study supports use of 2 controversial treatments for chronic fatigue”—CNN
“Chronic Fatigue Treatments Lead To Recovery In Trial”—Medical News
More skeptically, the Huffington Post asked, “To What Extent Can The Mind Heal The Body?” and pointed to the fact that behavioral therapy helps cancer patients as well, casting at least some doubt on the premise that improvements among those getting therapy indicates true healing.
The trial has influenced public health recommendations around the world. The CDC recommends cognitive behavioral therapy and exercise for ME/CFS, as do the British National Health Service, the Mayo Clinic, and Kaiser.
Questions emerge
For years, PACE encountered little criticism or skepticism from the media or, in public, from the scientific community. Patients pointed out flaws in the trial through academic and media sources, and asked for more data to analyze the claims, but their concerns were dismissed. Richard Horton, editor of The Lancet, attacked them as “a fairly small, but highly organised, very vocal and very damaging group of individuals who have, I would say, actually hijacked this agenda and distorted the debate so that it actually harms the overwhelming majority of patients.”
And then in October, David Tuller, a veteran health reporter who earned a doctorate in public health, and a lecturer in public health and journalism at UC Berkeley wrote a three-part analysis of the PACE trial, which described scientifically stunning problems. Among his observations: the final PACE definition of “recovery” was so weak that a patient could enter the trial with poor health scores, worsen on two of the four measurements, and still meet recovery criteria a year later. Objective criteria included in the original protocol, such as how far patients could walk in six minutes or whether they had returned to work, had been dismissed as irrelevant or unreliable in the final analysis. Tuller also collected a series of searing remarks about PACE by highly respected scientists across the U.S. and in England.
Who was included in the trial?
The original design of the study seemed poised to get some good answers. But problems started early during the recruitment process. It turned out to be more difficult to find appropriate patients who were interested in participating in the study than expected, and so the PACE researchers allowed patients with a higher level of physical function to enter the trial. This tweak was the first of many, each of which had the effect of improving measurements of success, regardless of how the patients fared.
Patients had to meet many criteria to be included in the trial, notably the following:
- Have chronic fatigue syndrome. Patients had to meet the Oxford criteria for CFS, which includes a broad range of people who feel very tired: Patients must suffer from severe and debilitating fatigue for over six months, and fatigue must be the main symptom of their problems. Depression, which can cause prolonged fatigue, was acceptable as a co-morbid condition, and was in fact quite common among the patients who were eventually included (33 percent). In addition, patients could not be diagnosed with another medical issue known to produce chronic fatigue, nor suffer from psychosis, bipolar disorder, substance misuse, an organic brain disorder, or an eating disorder.
- Have significant self-assessed fatigue. Fatigue was measured using the bimodal Chalder fatigue scale, which is discussed in some detail below. Patients had to score six or higher (out of 11) on this scale to enter the trial. The higher the number, the more fatigue a patient experiences.
- Have poor self-assessed physical function. Physical function was measured using the the short form-36 physical function subscale. For entry to the study during the first 11 months, one had to score 60 or below[2] out of 100; this threshold was changed to 65 or below during the trial, to recruit more patients. The lower the score, the worse physical function a patient has.
- Be able to travel to the hospital for treatment. This simple rule immediately excluded some of the sickest patients from participating in the trial, thus making any results generalizable only to the more functional patients with CFS.
The first issue with these criteria, as Tuller noted in the New York Times back in 2011 when he first started looking at PACE more closely, is their use of the Oxford definition, which requires no symptoms specific to the illness beyond fatigue. Most importantly, it doesn’t require the symptom that most experts consider the hallmark of the disease: the exacerbation of all other symptoms after exercise, or post-exertional malaise. It also doesn’t require other symptoms such as cognitive, sleep, or blood pressure regulation problems, nor neurological or immune problems. The Institute of Medicine cites several of these as “core symptoms” for ME/CFS. As a result, many specialists worry that PACE includes patients who suffer from other fatiguing illnesses but not ME/CFS, as described by other standard criteria.
This is a particular concern because the PACE entry criteria includes patients with depressive symptoms, and depressed people often exhibit symptoms similar to the Oxford criteria. The authors would need to take special care that the Cognitive Behavioral Therapy (CBT) branch of the study, for example, would not have inflated results thanks to the effective treatment of depression. If CBT had a particularly strong effect on people suffering from depression, one would see an impact on the whole group participating in CBT, because the average for everyone in the CBT arm of the study would go up.
The PACE researchers responded to this concern in a letter to the editor at the New York Times, saying it wasn’t valid for two reasons:
- The definition of CFS used for the study is clearly outlined, and the trial then applies to these people and others like them. The study doesn’t necessarily apply to a broader or different group of people diagnosed with ME/CFS under other criteria, but the PACE trial made no claim that it would.
- The statistical analysis included subgroup analyses of patients who met two other definitions—the Centers for Disease Control criteria for CFS and the so-called London criteria for ME. And the PACE authors reported that their main results held up under these alternative definitions.
To the first point, the authors certainly can point to defining CFS as meeting the Oxford criteria, as when Dr. Peter D. White, Professor of Psychological Medicine at Queen Mary, University of London, says that PACE “does not purport to be studying CFS/ME but CFS defined simply as a principal complaint of fatigue that is disabling, having lasted six months, with no alternative medical explanation (Oxford criteria).” Yet the trial and its analysis lie within a larger body of research and one can’t ignore the medical community’s picture of the illness. Media discussion of the PACE trial implied that the results generalize to the whole community, and the authors of PACE did much to encourage that misinterpretation. Indeed, both White and coauthor Professor Michael Sharpe of University of Oxford have extensively referred to patients as having “CFS/ME,” and Sharpe was recorded saying that that “the majority view is that people regard them as the same.”
Furthermore, the entry criteria excluded all patients who, at the time of initial assessment could not come to the hospital for visits—even if they would otherwise meet the PACE trial definition of having CFS. Since some ME/CFS patients report being so ill they cannot sit up, speak, or eat, this single exclusion for PACE restricts the participation of the sickest patients. And while the authors may have been clear that the trial refers to people with CFS as defined in their trial, they made little effort to explain the impact to the whole study of not including sicker patients who could not initially commit to the trial.
Tuller noted that this subgroup analysis doesn’t meet standard medical practice, as it selects patients who meet both the Oxford definition and the alternate definitions. Not all patients who meet the CDC or London criteria do meet the Oxford definition, however, because the Oxford criteria require that the primary symptom be fatigue while the other two do not. For example, patients could present with serious neurological or sleep problems as the primary symptom—not uncommon in more severe forms of the illness—and thus might not be included in the study. In such cases, the study’s results would not apply.
All together, these choices create what is called selection bias. One wants to study people with ME/CFS, but one selects a “sample” of people with ME/CFS who do not represent the whole. They may be more likely to suffer from depression, less likely to meet the clinical criteria for ME, more likely to be able to function a little bit, and less likely to have found an effective way to manage their illness.
Selection bias results in limited generalizability of any results. If Graded Exercise Therapy (GET) is effective for the sample population in the trial, how would it apply to a person who couldn’t even start on the treadmill because he or she has trouble sitting up?
Additionally, careful follow up with patients who did not finish the program needs to be provided, since patients who get sicker may have trouble returning to the hospital—and their data may not be included in the trial if they don’t complete the program.
Shifting recovery criteria
Here lies one of the most troubling aspect of the PACE trial. The study protocol, as originally stated, had clear points of comparison and a specific definition of both a “positive outcome” and “recovery.” Patients had to satisfy multiple criteria for entry into the trial, including abnormal scores on two subjective questionnaires involving self-assessment on fatigue and physical function.
The trial detailed both primary and secondary outcomes. The primary outcome was based entirely on the two self-rated questionnaires: one assessing fatigue and the other assessing physical function. Secondary outcomes were far more complicated; they included a list of four items that together form “recovery criteria,” and also include specific progress in externally-evaluated physical ability and economic status.
While the study was being carried out, the way that primary outcome measurements were analyzed and incorporated into “results” changed quite dramatically; and these changes had significant impact on the interpretation of the data. The secondary outcomes also shifted considerably from their original description: the definition of “recovery” was significantly weakened, and the physical performance scores and economic status measures were disregarded.
According to Simon Wessely, Professor of Psychiatry at Kings College London,“Small corrections to the route taken were made on the way, but these were of little significance.” Yet it seems that some of these corrections had such a major impact that they might have altered the results so as to be significantly more beneficial to patients than would have been found using the original criteria. Let’s take a look at how that works.
Recovery in PACE
The biggest concern for how PACE is designed relates to recovery criteria. The PACE researchers, again, claimed that 22 percent of patients who received CBT or GET “recovered,” a remarkably strong claim.
“Recovery” is a loaded word, especially with an illness known for its recurrence. The PACE authors have come under a lot of criticism for using “recovery” rather than “remission,” an oversight that they shrug off as a matter of people not reading their paper carefully enough. In other words, they mean “recovery from this episode” and not full recovery.
In addition, the PACE researchers changed their definition of “recovery” significantly over the course of the trial. In the 2007 protocol, a “recovered” patient had to meet all four of these criteria, taken from their article:
i. A Chalder Fatigue Questionnaire [bimodal] score of 3 or less
ii. SF-36 physical Function score of 85 or above,
iii. CGI [self-rated Clinical Global Impression] score of 1, and
iv. The participant no longer meets Oxford criteria for CFS, CDC criteria for CFS [n]or the London criteria for ME.
In their 2013 paper, they changed the trial criteria for recovery to this[3]:
i. A Chalder Fatigue Questionnaire [Likert] score of 18 or less (previously three or lower on the bimodal scale)
ii. SF-36 physical Function score of 60 or above, (previously 85 or above)
iii. CGI [Clinical Global Impression] score of 1 or 2, and (previously just one)
iv. The participant no longer meets Oxford case definition for CFS (the authors now change from Oxford criteria to Oxford case criteria, a less stringent definition of CFS)
Many others have noted that all four original criteria were weakened.[4]
Each criterion has changed from before, and each has a story behind its change. The direction is, in all cases, toward weakening the criteria for recovery—and thereby increasing the percentage of “recovered” patients.
Fatigue scale. One of the primary outcome measurements is whether patients improve in self-reported fatigue. Fatigue was self-assessed, and measured using the Chalder Fatigue Questionnaire, an 11-question form with four responses for each question about experiencing fatigue: “better than usual,” “no worse than usual,” “worse than usual,” and “much worse than usual.” The Likert scale associates the numbers 0-3 to these four responses, with 0 implying “better than usual”, and increasing scores for increasingly worse opinions about one’s fatigue. The Likert Chalder scale is a refinement of the bimodal Chalder scale; a measurement of “0-1” on the Likert scale is converted to a 0 on the bimodal scale and a “2-3” is converted to a “1.” One can imagine that 0 represents all answers suggesting “not worse” and 1 represents all answers indicating “worse.”
A little arithmetic reveals that many PACE-qualifying scores on the bimodal scale (6 or greater) overlap with “recovered” scores on the Likert scale (18 or less). By 2013, a score of 18 or less was called “within the normal range” and a score higher than that “abnormal”. Here are some equivalences among the PACE-qualifying bimodal scores to illustrate how the conversion works; all of the blue scores below are considered bad enough to qualify for PACE yet also good enough to be considered “normal range.” If the PACE authors had stuck to a single rating system for their primary outcomes, patients would not have been able to qualify for PACE and also qualify for this particular recovery criterion with the same score.
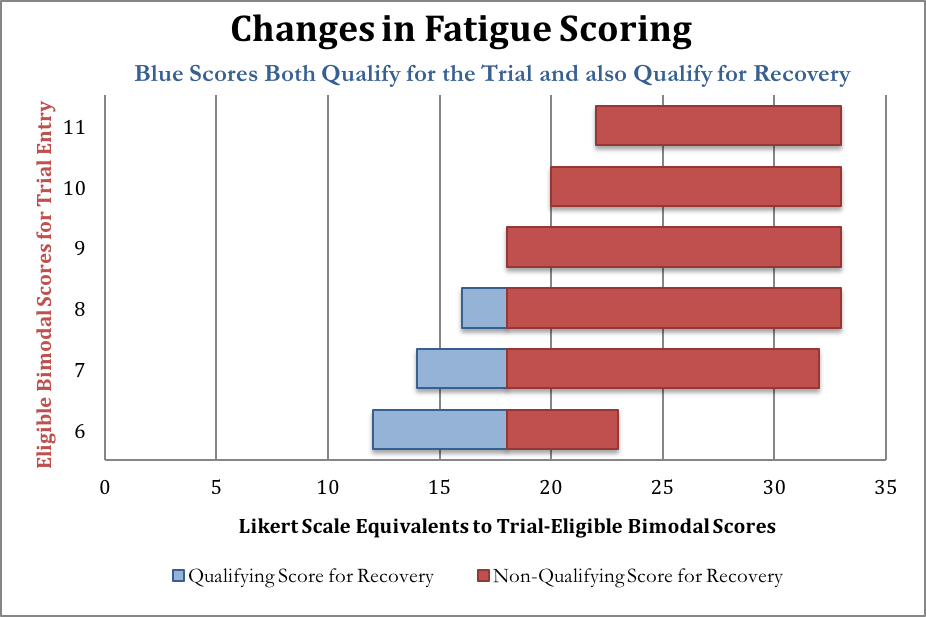
After entrance to the study had already been confirmed, the researchers eschewed the bimodal score used in 2007’s Criterion i, and reassessed the responses of patients when they entered the trial, using the Likert score in 2013’s Criterion i, shown along the horizontal axis of the chart above. PACE does not report how many patients’ fatigue scores fit into the “recovered” category after the responses were graded with the Likert scale.
To understand Tuller’s point that recovery criteria overlap with entrance criteria, consider someone with a “6” on the original bimodal fatigue scale This score is high enough to allow the person to enter the PACE trial if they also meet the other criteria. That score may correspond to a score anywhere between 12-23 on the Likert scale, depending on how the patient answered the questions. But if the person scored anywhere between 12 and 18, they would be considered in the “normal range” on the Chalder fatigue test, according to the newer recovery criteria. Yet people with these scores were not excluded from the study when the newer recovery criteria were introduced.
While overlapping sick and recovered criteria makes interpretation of the data difficult or impossible to interpret, another concern with the Chalder scale casts doubt on the data itself. It’s called the ceiling effect.
Remember that each question asked in the Chalder questionnaire is scaled from 0 to 3, where 3 is “much worse than usual.” But what if, over a year, you get even worse?
Let us suppose for a moment that 100 people are experiencing extreme fatigue. They each answer “much worse than usual” on the Questionnaire (a 3) to all 11 questions, resulting in a score of 33. Over the course of a year, there are random fluctuations in their health—half get worse, and half get better. Now they take the questionnaire again. Those who get worse still answer “3” to all questions (final score: 33). Those who improve now answer a “2” to all questions, stating that they are just “worse than usual” but not “much worse” (final score: 22). The new average is now 27.5, a significant improvement over the original score of 33.
This phenomenon is known as a “ceiling.” If one enters the PACE trial measuring your fatigue levels as “much worse than usual,” and the symptoms get worse, you have no way to record them in the scale, since the maximum is “much worse than usual.” Since the fatigue scores were very high on initial assessment, this ceiling affect could be quite dramatic.
We asked the PACE authors about this ceiling issue, and one author responded that they measured patients’ worsening in other ways (specifically, through the SF36 and CGI scores, discussed below). Certainly, these may have captured some worsening of patients, but these other metrics do not specifically measure the worsening of fatigue.
Most importantly, without looking at the data at all, the change in Criterion i results in an increased number of people who satisfy it. The 2007 criterion for recovery requires a bimodal score of 3 or less, which corresponds maximally to a Likert score of 17. In other words, all people who satisfy the 2007 Criterion i will automatically satisfy the 2013 Criterion i, yet the converse is not true: some people will meet the 2013 standard who would not have met the 2007 standard. In other words, by construction, the 2013 criteria for recovery will incorporate people who would not be considered “recovered” by the 2007 criteria, without excluding anyone considered recovered by 2007 criteria. The result of the change invariably leads to a better interpretation of health improvements for those participating in PACE.
At least a priori, the resulting improvement has no more impact on GET and CBT than it has on the other two arms of the study, however if the changes to the criteria and the resulting increasing number of “recovered” patients are sensitive to treatment type, then these recovery criteria will indeed create a skewed outcome in favor of these two therapies.
Physical Function. The physical function criterion is even more obviously flawed than the fatigue scale, as there is no need to convert responses from one scale to another. The original 2007 Criterion ii is a score of 85 or above but it was changed in 2013’s Criterion ii to a score a 60 or above. A lower number implies less physical function. When that cut-off score was changed to a 65 to recruit more patients, patients could enter with a score of 65 and be considered recovered with a score of 60 or higher!
A score of 60 is comparable to an average 75 year old, including sick 75 year olds, according to the 1999 study the PACE authors themselves used to justify claims about normative data for the Physical Function scale. Here’s a visual representation of the mean scores, and the for people of different ages, and the trial entry and recovery scores used by PACE. The red bar indicates the entry-level maximal score. The dark blue bars represent the “recovery” level from 2013, and the comparatively similar scores for 75-84-year olds, including sick people.
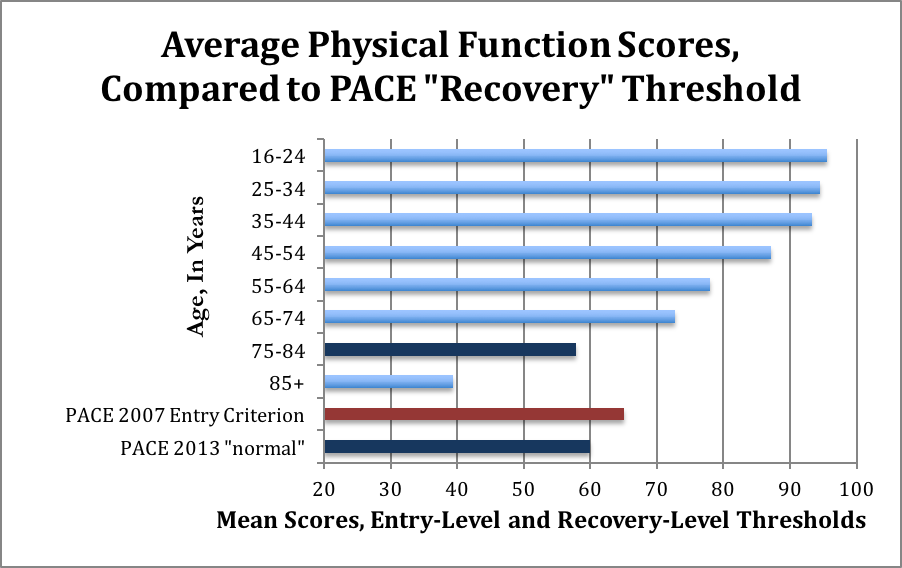
The average age of participants in the PACE trial is about 39 years old; these normative data suggest that people in this age group should have SF-36 scores of about 93. Yet the new 2013 “normal range” requires only a score of 60.
The justification given for the change in protocol is itself based on the same 1999 study:
“We changed our original protocol’s threshold score for being within a normal range on this measure from a score of ≥85 to a lower score as that threshold would mean that approximately half the general working age population would fall outside the normal range…. We derived a mean (S.D.) score of 84 (24) for the whole sample, giving a normal range of 60 or above for physical function.”
This statement is factually incorrect. In fact, more than 80 percent [5] of the British working-age population (including chronically ill people) score 85 or above. The PACE researchers appear to have made a very basic mathematical error: confusing the median and the mean. The median is the number at which half the people have higher, and half the people have lower, physical function scores. The mean is the average. Because a small number of people have very low physical function scores, in this case, the mean is far lower than the median.
The PACE authors decided what the “normal range” should be based on the average (84) for the entire British population age 16 and older. This population is very different from the PACE participants. The mean score (standard deviation) for the working-age population in the same study is approximately 90 (17).[6] Had the PACE authors used these figures, the threshold score for “normal range” using their reasoning would have been 75.
PACE does not report the SF-36 physical function scores for those who are “recovered,” nor do they report the number of people with SF-36 scores 85 or above.
The Clinical Global Impression scale (CGI). The CGI is a rating from one to seven, given by a trained clinician, answering this question: “Compared to the patient’s condition at admission to the project, this patient’s condition is:
1=very much improved since the initiation of treatment
2=much improved
3=minimally improved
4=no change from baseline (the initiation of treatment)
5=minimally worse
6= much worse
7=very much worse since the initiation of treatment
As can be seen by the third recovery criterion, the CGI criterion toward recovery changed from “1” to “1 or 2”. The authors explain they made the change, “because we considered that participants rating their overall health as ‘much better’ represented the process of recovery.”
This change is the sort that raises the question of why the authors devised their original criterion if they felt that “much better” was good enough. Similarly, it is disturbing that a “recovery” criterion is one the authors “considered” to represent a “process” rather than a recovery. Since ME/CFS is a disease noted for the considerable relapses, long term patients are bound to have period in which they feel some improvement.
Yet, even putting aside these considerations of whether the 2007 Criterion iii, or the 2013 Criterion iii, is more clinically appropriate, changing this criterion will still increase the number of patients meeting recovery criteria.
The number of patients whom the changing recovery criteria impacts may not be independent of treatment. Any decision to change or not to change the CGI recovery criterion may have a greater impact on some of the arms of the study as compared to others. Perhaps patients who are in the CBT branch of the study are more inclined to speak positively of the direction of their health with their clinicians, compared to those in APT, resulting in more “much improved” ratings.
The ME/CFS criteria for recovery. The change in the fourth criterion for recovery is the strangest of all, and points to confusion about the qualification for entry. This requirement sounds extremely impressive—the patients no longer have CFS!—but in fact, patients who met the first three criteria may have automatically met this one as well.
In the changes to the protocol in 2013, the authors added a requirement to all the definitions of ME/CFS (Oxford, London ME, and CDC) that patients also had to meet the trial entry requirements for the fatigue and physical function scores. In other words, the 2013 Oxford “case” definition of CFS had three criteria:
- meeting the Oxford criteria for CFS AND
- having a physical function sore of 65 or lower/worse AND
- having a bimodal fatigue score of 6 or more/worse
Overall impacts of these changes
For the sake of illustration, we can imagine someone who came into the study with extreme and debilitating fatigue, scoring a 6 on the bimodal fatigue scale, and 65 on the physical function scale. The person meets the clinical definition of CFS according to the Oxford criteria, but is generally an upbeat person. While in the trial, she has not improved in her overall fatigue or her physical function, but she is quite happy to be getting expert medical care, and she is also sleeping a little better thanks to sleep medications. She rates herself as “much improved”, but not “very much improved” on the CGI, but she records no differences in her assessments of physical function or fatigue. She still cannot walk a mile, remember her words, or hold a job. Yet she is a case of someone who has “recovered” thanks to the CGI. And unfortunately, one could imagine that someone participating in the CBT branch of treatment might be more likely to cast themselves as improving, if only for the sincere desire to minimize the impact of the illness, as instructed by the cognitive behavioral therapist.
PACE author explanations
In multiple interviews and in the papers in which the changes were discussed the PACE authors noted that these changes were made before any data had been seen, and under the approval of an oversight committee.
However, each of the changes in protocol made the criteria for recovery easier to meet. You would not need to see the data to know that more patients would meet recovery criteria under the new, lowered bar. It’s like going to a middle school and defining “tall” to mean above 5’9”, and then before checking how many people qualify as “tall,” you change your criterion to 5’5”. You don’t need to know the heights of the people at the school to know that there will be more “tall” people. It’s definitional.
Furthermore, the PACE authors’ explanation doesn’t address the core questions: are these changes clinically justified, and did they increase the ascribed benefit to treatment, regardless of the actual data?
The PACE authors point to their data: more participants qualified as “recovered” under CBT and GET compared to the other two treatments. However, if the changes to the criteria and the resulting increasing number of “recovered” patients are sensitive to treatment type, then these recovery criteria will indeed create a skewed outcome in favor of these two therapies.
The authors have also argued that they’ve been very clear that “trial recovery” is not the same as “recovered.” But the word choice certainly leads to a lot of unnecessary confusion, and at best it’s disingenuous to call this “recovery” even with a made-up definition that may only reflect “tiny progress”.
Changes in “primary outcomes” in the PACE trial
The original PACE protocol’s primary outcome is stated as follows:
- A positive outcome will be a 50% reduction in [bimodal, Chalder] fatigue score, or a score of 3 or less.
- We will count a score of 75 (out of a maximum of 100) or more [on the SF-36 physical function sub-scale], or a 50% increase from baseline in SF-36 sub-scale score as a positive outcome.
- “Overall improvers” are those who meet both of the above primary outcome measures.
The primary outcomes are based entirely on self-assessed progress, and are related to the “recovery” criteria used as a secondary measurement. The original plan was to compare the number of overall improvers, as well as the number of positive outcomes in each of fatigue and physical function, across the different arms of the study.
The fatigue criterion for a positive outcome is over-described, in the sense that it is mathematically equivalent to “a 50 percent reduction in fatigue score.” Recall that the fatigue score was evaluated on the bimodal scale upon entry to the PACE trail, with values ranging from 0 to 11. Six or higher was the entry-level score. Thus obtaining a 3 or lower is already a reduction of at least 50 percent of the score. Someone who starts with a 10, for example, would have a positive income if they subsequently score a 5.
For the physical function questionnaire, PACE entrance requires one to have a 65 or lower on the scale. “Positive outcome” would be a score of 75 or higher, or 50 percent improvement: if someone scores a 40, and subsequently scores a 60, this would be considered a positive outcome even though it is a fairly low score.
Keep in mind that a “positive outcome” is different than meeting “recovery” criteria, even in the original protocol. The positive outcomes are only improvements on the fatigue and physical functioning scales, described in the 2007 protocol. Yet this positive outcome represented enough benefit to justify recommendations for treatment for patients with ME/CFS.
The new plan? As put in the 2011 paper published in the Lancet,
“We used continuous scores for primary outcomes to allow a more straightforward interpretation of the individual outcomes, instead of the originally planned composite measures (50% change or meeting a threshold score).”
Just to tease out what this means: instead of using a yes/no for meeting a “positive outcome” criterion for fatigue, the authors decided to compare the scores on the fatigue questionnaire across the groups (they also used the Likert scale rather than the bimodal scale to make this comparison). Instead of using a yes/no for meeting a “positive outcome” for physical function, the authors decided to compare the actual scores. The new statistical plan is to compare the average scores and see which group does better.
A priori, there is no obvious better choice of how to characterize whether one treatment is “better” than another: the first method measures which arm has a larger proportion of people who meet a specific threshold, and the second method characterizes which arm sees more improvement of scores. The appropriate choice might initially be a matter of which has more clinical importance. The advantage of the yes/no characterization is that it measures whether a particular treatment would get patients above the specified threshold, perhaps one that has meaning in the context of this particular illness. On the other hand, a disadvantage to the yes/no characterization is that it cannot measure improvements that stay below this threshold, nor improvements that occur above the threshold. Someone who starts with a physical functioning score of 60 and on year later attains the score of 95 counts the “same” as someone who attains a 75 on the physical functioning score, even though a 95 is much higher. Similarly, an improvement from 40 to 55 on the physical functioning score would not count as a “positive outcome.”
The noted Columbia University statistician Andrew Gelman observed that a continuous measurement – even one determined after the trial started—is an appropriate way to report results, especially if there is a lack of statistical significance in individual results. Yet a statistical test that failed to show significance should still be reported, and the PACE authors have not provided an answer to whether the original way of measuring “positive outcomes” would also result in determining GET and CBT are better therapies than APT and SMC.
However any change in a statistical plan brings an elephant into the room: why did the authors decide to use the continuous scores? There is little evidence to support the claim that the authors purposely did this because their original protocol yielded no results. The PACE authors point out that the continuous results are easier to interpret; they consist of a direct comparison of groups and which treatment had more success as reported by the patients. But why did the authors make this decision mid-trial, rather than at the beginning, and why didn’t they also provide the results based on the original criteria, or at least conduct a sensitivity analysis to identify how dependent the outcomes are on these different ways of describing the data? What invalidated their original planned analysis, even if the authors determined that comparing improvement provided a “better” analysis?
And what of the clinically relevant aspect of the analysis? In eschewing their original definition of “positive outcome,” the authors claim in their 2011 paper:
“A clinically useful difference between the means of the primary outcomes was defined as 0·5 of the SD [standard deviation] of these measures at baseline, equating to 2 points for Chalder fatigue questionnaire [Likert scale] and 8 points for short form-36. A secondary post-hoc analysis compared the proportions of participants who had improved between baseline and 52 weeks by 2 or more points of the Chalder fatigue questionnaire, 8 or more points of the short form-36, and improved on both.”
The reasoning here may be a bit fuzzy: the clinically useful improvement involves numbers determined by the other patients in the trial: the standard deviation of fatigue scale scores for all the PACE trial patients is about two points, therefore the post-hoc analysis looked at the proportion of patients reaching this benchmark. This makes little sense. Wouldn’t proportional improvement be based on positive outcomes that are determined by clinically relevant assessments of healthy ranges?
The question of clinically meaningful measurements gets further confused as we try to ascertain the meaning of the numbers. The data show that CBT and GET groups improved over APT and SMC groups in both fatigue and physical function. Yet even the improved groups seem to have very poor scores, leading to concern that any improvements aren’t clinically meaningful.
The authors of PACE note that they never changed the outcome measurements. True! The measurements are simply the answers to the questions on each of the questionnaires. But the way the measurements are used was changed significantly: from a binary outcome (a “positive outcome” or not) to a continuous measurement of who had a higher score. On the one hand, a continuous measurement can show more subtlety and contains more information. On the other hand, the continuous measure may show “improvement” when it’s not clinically significant. This is the claim from several patient advocacy groups.
Conclusions on PACE study design
The PACE design changed so significantly as to leave many wondering whether there is value in the study itself.
How can we judge whether the improvements seen in primary and secondary outcomes associated with CBT and GET are “real” if “recovery” does not always require clinically meaningful improvement, and if the meaning of “normal range” includes averages for people in their late 70s and early 80s?
How can we judge whether improvements are real when they are only self-assessed? APT is described as “based on the theory that one must stay within the limits of a finite amount of ‘energy,’” while CBT includes, “collaborative challenging of unhelpful beliefs about symptoms and activity.” Will these different philosophies result in different patient self-rated overall well-being and relative improvement over the year in the study?
How do we know if GET is helping ME/CFS patients more than other therapies, when exercise is known to help with depression, and patients with depression manifesting as fatigue (and not ME/CFS) may have entered the participant pool?
How can we generalize to the patients with ME/CFS who are too sick to travel to the hospital, if all PACE participants are able to attend hospital visits?
How do we contextualize major changes in protocol impacting results, and the unwillingness of the PACE authors to provide outcomes based on the initial planned data analysis? Do these changes impact patients in particular branches more than in others, biasing the study’s outcomes?
It seems that the best we can glean from PACE is that study design is essential to good science, and the flaws in this design were enough to doom its results from the start.
—
[1] Wolfson Institute of Preventive Medicine, Barts and The London School of Medicine, Queen Mary University of London, London, Mental Health and Neuroscience Clinical Trials Unit, Institute of Psychiatry, King’s College London, London, UK, Medical Research Council Biostatistics Unit, Institute of Public Health, University of Cambridge, UK, Medical Research Council Clinical Trials Unit, London, UK, South London and Maudsley NHS Foundation Trust, London, UK, Faculty of Health and Well Being, University of Cumbria, Lancaster,UK, Nuffield Department of Medicine, University of Oxford, The John Radcliffe Hospital, Oxford, UK, Royal Free Hospital NHS Trust, London, UK, Barts and the London NHS Trust, London, UK, Frenchay Hospital NHS Trust, Bristol, UK, Western General Hospital, Edinburgh, UK, Centre for the Economics of Mental Health Service and Population, King’s College London, London, UK Academic Department of Psychological Medicine, King’s College London, London, UK, and Psychological Medicine Research, School of Molecular and Clinical Medicine, University of Edinburgh, Edinburgh, UK.
[2] The authors eased the entry criteria to improve recruitment.
[3] The authors define both trial and clinical recovery criteria, which are similar except for the final criterion about which set of criteria are used to determine if the patient has CFS any longer.
[4] The authors claim in 2013 to have only changed three criteria for “clinical recovery”, however their 2007 paper referred to definitions of CFS and ME that are different than the operationalized definitions in the 2013 paper.
[5] Matthees A, (2015). Assessment of recovery status in chronic fatigue syndrome using normative data.Quality of Life Research 24 (4) pp 905-907. [link]. A previous version of the text said 90 percent, which was the percentage of healthy working age people; the text has been emended to 80 percent to include the chronically ill. Thanks to George Faulkner for pointing out the error.
[6] Bowling A, Bond M, Jenkinson C, Lamping DL (1999). Short Form 36 (SF-36) Health Survey Questionnaire : which normative data should be used? Comparisons between the norms provided by the Omnibus Survey in Britain, the Health Survey for England and the Oxford Healthy Life Survey. Journal of Public Health Medicine 21, 255–270.

Please note that this is a forum for statisticians and mathematicians to critically evaluate the design and statistical methods used in studies. The subjects (products, procedures, treatments, etc.) of the studies being evaluated are neither endorsed nor rejected by Sense About Science USA. We encourage readers to use these articles as a starting point to discuss better study design and statistical analysis. While we strive for factual accuracy in these posts, they should not be considered journalistic works, but rather pieces of academic writing.
Rebecca – thanks so much for covering this important topic. I’m only partway through but wanted to alert you to the fact that in your section, “Questions emerge”, para. 2, the three links to Dr David Tuller’s important PACE critique are not live.
Thanks Sasha. The links have been updated. Thank you again
Thanks for a very well researched article. Just a minor point – there is no hyperlink to the Tuller 3-part articles
Thank you Anna. We have updated the links. Thanks again.
Thank you for this article. An important point is that the PACE trial did not contain a placebo control group. I think few would consider such a design to be the gold standard. Especially when the primary outcomes are subjective and therefore easily influenced by factors other than the treatment.
Dr. Goldin, thank you for a strong and clear analysis of the PACE trial’s experimental design fatal flaws. In a related matter, the US NIH is about to embark on a purported “definitive” study of CFS/ME, the proposed design and sample size of which appear potentially problematic. I urge you to make a critical appraisal of the proposal (available online) now, before limited dollars and effort are spent on it.
Dear Dr Goldin,
Thank you for an excellent exposition of the detailed weaknesses in the PACE design. (I am one of those who wrote the original letter to the Lancet.) I realise that you are a statistician and focus on statistical issues but what I find puzzling about this case is an almost universal focus by commentators on these details rather than the much greater flaw in the trial – the absence of blinding in a study with subjective outcomes. (I do not mean to be critical, I am just puzzled.) If everything you comment on had been handled with care the trial would still be valueless.
You point out that the trial was, in theory, controlled. However, as a scientist I don’t think this counts as controlled. If I study a monoclonal antibody in an immunofluorescence assay I may use an irrelevant antibody of the same isotype as a control. The justification is something like: a control, as far as is possible, should mimic any behaviour of the test agent due to non-specific effects inherent in the experimental context, and thereby reveal any truly specific effects of the test agent. For therapeutic trials it has been agreed for the last thirty years or so that where primary endpoints are subjective an adequate control must take into account the various factors that can lead to spurious indications of efficacy, commonly bundled under the placebo effect, although the problem is much more complex. Otherwise it is not actually a control in the spirit of scientific investigation.
In this particular study this problem is about as acute as it can get because the treatments being promoted by the investigators (literally in newsletters to patients) included encouraging patients to think they would get better. As Knoop has said, CBT in a sense is a deliberate placebo, trying to make use of psychological pressure on belief patterns. A control would have to include exactly the same level of encouragement to believe in getting better and this was notably absent in the two ‘control’ arms. So the trial looks pretty much to be a self-fulfilling placebo exercise. If this was a pharmacological study and had not been blinded no physician would take it seriously. It resembles the physiotherapy trials we used to have in rheumatology that died out because scientific standard were raised. If this study were to be presented at journal club in a medical unit, rather than a psychiatric unit, it would be torn to ribbons by the junior registrars – that sort of thing that gets flagged up by newspaper column writers who specialise in ‘bad science’.
And what worries me most is that colleagues of the PACE team have approached me indicating they do not understand why this is a problem. My suspicion is that Pandora’s box is not even halfway open yet.
I agree with Dr. Edwards about the lack of ‘control’ of PACE- In fact I think this is why the original Lancet paper refers to PACE only as ‘a randomised trial'(1) instead of the ‘randomised controlled trial'(2) PACE touts itself to be in the original trial protocol.
The title of the protocol(2) also calls into question Prof. White’s comments that PACE “does not purport to be studying CFS/ME but CFS defined simply as a principal complaint of fatigue that is disabling, having lasted six months, with no alternative medical explanation (Oxford criteria).” If PACE ‘doesn’t purport’ to be studying CFS/ME then why does the published trial protocol as well as virtually all other documentation about the trial explicitly refer to ‘chronic fatigue syndrome/myalgic encephalomyelitis or encephalopathy’?
1. Comparison of adaptive pacing therapy, cognitive behaviour therapy, graded exercise therapy, and specialist medical care for chronic fatigue syndrome (PACE): a randomised trial
http://www.thelancet.com/journals/lancet/article/PIIS0140-6736%2811%2960096-2/abstract
2. Protocol for the PACE trial: A randomised controlled trial of adaptive pacing, cognitive behaviour therapy, and graded exercise as supplements to standardised specialist medical care versus standardised specialist medical care alone for patients with the chronic fatigue syndrome/myalgic encephalomyelitis or encephalopathy
http://bmcneurol.biomedcentral.com/articles/10.1186/1471-2377-7-6
> And what worries me most is that colleagues of the PACE team have approached me indicating they do not understand why this is a problem.
I’ve noticed others struggling to understand why this is a problem, so I wrote an essay that leads up to the issue slowly (reading time: eight minutes): http://www.cawtech.freeserve.co.uk/treatfection.2.html
My angle on the issue is to ask whether the therapist was successful in delivering Cognitive Behavioural Therapy? Did the patients cognitive behaviour change? The patient could self-report their cognitive behaviour by filling in a form. But isn’t that what they already do? Doesn’t PACE measure *delivery* more than *outcome*?
Thanks for your comments! I agree that using only subjective outcomes is a major flaw in an unblinded study. One reason that I didn’t focus on this aspect of PACE in the piece I wrote is that plenty of research – some highly regarded – is done with subjective outcomes and without blinding, and without receiving the same kind of outrage coming from patients/advocates/researchers following this trial. This includes research on depression, anxiety and stress, as well as research in the field of education, and many, many experiments in psychology. One ME/CFS friend I knew many years ago said to me, “You know, I would be thrilled to find out my problems were entirely psychological! That would be way easier to fix!” Indeed, were patients facing an illness greatly improved by CBT and GET, as measured by serious improvement on subjective measurements in the context of an otherwise well-designed study, I think there *would* be some validity, especially in then following up to determine whether there are also some objective improvements. Instead, the metrics for PACE “recovery” are farcical, even if we accept that subjective improvement is valuable.
The original PACE design did not have only subjective measures. But of course, it was changed. The more “objective” measures were either not followed up on, or not reported — and even the condition “having CFS” (by any of the various criteria) was changed from something sort of objective, to something trumped by a minor subjective improvement (slightly less self-reported fatigue or slightly more self-reported physical function). This results from the PACE team’s change in the 4th criterion for “recovery.”
I do not have evidence that the authors had planned from the outset to share literature with the patients, and for this reason didn’t lump it under the umbrella of “study design”, though perhaps I should have in retrospect — especially considering that those patients in the CBT and GET arms of PACE received messaging about how it’s in their power to get better, while the APT group did not. For sure, the risk that CBT has a placebo effect is well-known: much psychological research on CBT insists on a “placebo” that is similar to CBT but isn’t quite the same, in order to compare. At the time that I mapped out this piece, I figured I might write another piece on the way the introduced bias (both the treatment messaging and the newsletter distributed during the trial) would/could influence the results. Certainly, you are right: lack of objective metrics in an unblinded trial is another way that the PACE design was, from the outset, at risk for meaningless data.
Thanks Rebecca for your time and effort to write this article.
It is telling that even in such a lengthy analysis there are still some flaws which aren’t discussed.
To say the flaws in design were enough to doom this trial from the start is certainly true, however it seems they have pulled the wool over many peoples eyes.
It is a sad reflection on the media / journalism profession that so few have taken up the mantle to investigate, ask questions and report the facts.
The damage caused by this trial and the press releases may never be undone.
It is only articles like this that can help start the process, so once again many thanks.
Thank you so very much for clearly stating the many problems with the PACE trial. Unfortunately it is impossible to overstate the negative impact PACE has had on the perception of this disease in the medical arena as well as the rest of society. As a result biomedical research has been stymied and patients left without answers and help. On top of coping with a devastating disease, patients often have to face disbelief and ridicule. This is an ongoing tragedy that needs to change. Thank you for being part of that change.
Thank you for this thorough and factual examination of the PACE trial’s methodology. I would like to add two points to the discussion:
1. As pointed out by Professor Jonathan Edwards, the trial is fatally flawed from the outset due to subjective outcome measures for the primary endpoint and the lack of blinding. This would never be accepted in any clinical trial of a pharmaceutical.
2. “The PACE design changed so significantly as to leave many wondering whether there is value in the study itself.”
The authors themselves admit there is no value in the study:
“There was little evidence of differences in outcomes between the randomised treatment groups at long-term follow-up.”
http://www.ncbi.nlm.nih.gov/pubmed/26521770
This is a startling admission that deserves its own headline. Instead, it has been largely buried and forgotten, while the scientific establishment continues to promote harmful GET and useless CBT.
Speaking as a patient on the trial I can tell you that there was no ‘specialist medical care group’ this was in fact a group that was offered nothing. I was in this group and I didn’t even have a review with my doctor – nothing, I didn’t see my doctor so to call it a specialist medical care group is a bit of a stretch of the imagination. If you were in this group you were left alone. Also I’ve never been followed up so when they pull out these new studies on the research and patient progress every 2 years or so they are being very selective about who they follow up therefore how can any conclusions be fully representative of the trial?
If the trial design included a comparison group called “No Care” it would’ve been rejected as unethical. But label the same group as “Specialist Medical Care” and magically everything’s great.
Thanks for posting this. There has been some talk in patient forums about how to collect the experiences of trial participants. Your post underscores the importance of hearing from participants who wish to come forward. I wonder if the meaction.net website would be a good place to collect these stories.
Gemma, I urge you to contact #MEAction UK or the ME Association with your story. It should be published and shared widely.
They carried on collecting the data through the trial. And it still exists. So. Given time and funding that data could be used again in the original ways anticipated, and we could see what falls out then?
Thank you for the excellent article, Rebecca. Well written and easy for a non-statistician to understand.
Just two comments –
First, your article noted that “patients could not be suffering from “primary” depression or anxiety.”
However, the Oxford criteria only excludes “a current diagnosis of schizophrenia, manic depressive illness, substance abuse, eating disorder or proven organic brain disease” and states that depressive illness and anxiety disorders “are not necessarily reasons for exclusion.” Oxford does not state that primary depression is excluded and the PACE protocol and the 2011 publication do not appear to either. This means that PACE’s patient selection methods could have included patients who did not have ME/CFS but did have psychiatric conditions or other forms of fatiguing conditions that might have been helped by these therapies. Notably, 2015 reports by Health and Human Services said that the Oxford definition included patients with other conditions and called for the Oxford definition to be retired because it “may impair progress and cause harm.”
The second comment is that in addition to the problems you noted with the claim that PACE demonstrated the same response for patients who met alternative definitions of CFS and ME, its worth noting that the alternative definition used for CFS in PACE had been modified to only require symptoms for 1 week, not six months. The PACE investigators themselves acknowledged that as the diagnosis by the alternative CFS definition could have been “may have been inaccurate because we only examined for accompanying symptoms in the previous week, not the previous 6 months.”
Uninterpretable results on an ill-defined patient population.
Tragically, this has a real life impact to patients. As you note, PACE is used to support recommendations for CBT and GET in evidence based clinical guidelines. This is true even in recently updated clinical guidelines such as those from UpToDate, which recommend the stricter diagnostic criteria published by the Institute of Medicine in 2015, criteria that require hallmark symptoms like post-exertional malaise and yet still recommend PACE and CBT and GET for treatment. This creates a significant risk of harm to ME patients.
It is questionable whether all changes to the published trial protocol were approved:
While the investigators stated that the recovery criteria was changed before the analysis was conducted [1] and therefore should be regarded as “pre-specified” [2], there is evidence suggesting that it was changed well after the investigators were already familiar with the distribution of scores for each component of the recovery criteria, including access to summary statistics and histograms:
a) Before appearing as part of the revised recovery criteria, the controversial post-hoc ‘normal range’ for fatigue and physical function appears to be first introduced during the peer review stage [3] of the 2011 Lancet publication on the main trial results (well after the authors were unblinded to trial data). [4]
b) The statistical analysis plan outlines the final planned or pre-specified analyses that were approved prior to database lock and unblinding of trial data, but does not mention changes to the recovery criteria. [5] It describes the summary data they had access to early on when preparing the first paper on the main results. It discusses the possibility of future post-hoc changes and exploratory analyses, including those based on trial data.
c) Changes to the primary outcomes were approved by an oversight body (e.g. Trial Steering Committee) [5] but there was no confirmation that the revised recovery criteria was similarly approved, not in the paper itself [1] or the investigators’ response to David Tuller when the issue of changes to the recovery criteria was raised. [4] Note that statements in the PACE trial literature about approval of changes typically refers to the main changes to the primary outcomes, not specifically to the revised recovery criteria. When referring to the overlap between the normal range for fatigue and physical function, with the trial eligibility criteria for severe disabling fatigue, Bruce Levin (Professor of Biostatistics, Columbia University) has stated: “I find it nearly inconceivable that a trial’s data monitoring committee would have approved such a protocol problem if they were aware of it.”. [6]
d) The original primary outcome i.e. positive outcome was the proportion of individuals meeting a threshold, but the new primary outcome was group-level averages; in other words the new primary outcome was not a direct replacement of the original. The closest (but much less stringent) equivalent to the original primary outcome is the secondary outcome for individual-level “clinically useful difference” (CUD). But this was also described in the Lancet publication as a post-hoc analysis [4] and not mentioned in the statistical analysis plan either [5] (group-level CUD is mentioned and approved) so it remains unclear if it was explicitly approved by the Trial Steering Committee.
The PACE investigators have not reported all pre-specified outcomes and have not provided adequate details about the timing of the changes; this is contrary to modern expectations of researchers (e.g. see AllTrials.net and compare-trials.org). A FOIA request to clarify this issue and make sure a possible post-hoc or exploratory analysis was not being misleadingly described as a pre-specified, was dismissed as part of a “vexatious” campaign. [7] The PACE investigators stated that the trial would be conducted in accordance to the Declaration of Helsinki, however, the refusal to clarify the timing of changes to the protocol is equivalent to withholding information about methods, which is against the declaration. [8]
The changes to the protocol were (generally) poorly justified, and the change to the threshold for normal physical function was demonstrably erroneous. The stated justification for this drastic change, incorrectly asserted that about half the general working age population score under 85, but it is actually 17.6%, so the change was unjustified. Note that 92.3% of the working age English population who do not report chronic disabilities score 85 to 100, and 61.4% score the maximum of 100, with scores under 80 being extreme outliers. [9,10] Again, PACE investigators claim that attempts to raise these issues and have them corrected are simply part of a “vexatious” campaign. [11,12]
1. http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3776285
2. http://www.virology.ws/2015/10/30/pace-trial-investigators-respond-to-david-tuller
3. http://www.meactionuk.org.uk/whitereply.htm
4. http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3065633
5. http://www.ncbi.nlm.nih.gov/pmc/articles/PMC4226009
6. http://www.virology.ws/2015/10/21/trial-by-error-i/
7. https://www.whatdotheyknow.com/request/timing_of_changes_to_pace_trial
8. http://www.ncbi.nlm.nih.gov/pmc/articles/PMC4396123
9. http://link.springer.com/article/10.1007%2Fs11136-014-0819-0
10. http://www.bmj.com/content/350/bmj.h227/rr-16
11. https://ico.org.uk/media/action-weve-taken/decision-notices/2015/1043579/fs_50558352.pdf
12. http://www.thelancet.com/journals/lanpsy/article/PIIS2215-0366%2815%2900114-5/fulltext
Correction for the first sentence of my previous comment: “It is questionable whether all changes to the published trial protocol were made before unblinding of trial data and approved by the Trial Steering Committee (etc):”
“We changed our original protocol’s threshold score for being within a normal range on this measure from a score of 85 to a lower score as that threshold would mean that approximately half the general working age population would fall outside the normal range.”
This quote is just insane gibberish. If that were the case, they would have changed the score to 80 not 60. As can be seen from the chart, the other half of the general working age population that they supposedly wanted to incorporate pretty much all fall between scores of 80-85. Only people 80 years old and above on average score as low as 60. 80 years old is far above the working age.
In any case, when you have patients of a range of ages and a score that varies by age, then you can’t use one same number to judge the recovery of all patients of different ages. The working age population is 15-64. Even the score of 85 which would be recovered for someone older than 50 would not be recovered for a 15 year old or even fully recovered for people younger than 50.
For those that found Goldin’s analysis interesting, you might also be interested in: https://docs.google.com/document/d/1AqCB7ZywQGYyR8fz5QICu4PDHvJt_RXjebNJah_Dz7U/edit?usp=sharing
Which also challenges White et al’s ‘reasons’ for changing the Primary Outcome Measures
Thank you. Stats lie in your wheelhouse and we non-statisticians depend on your skills and interest in applying them to validate claims. This was informative and easy for the layperson to understand.
Thanks very much for this useful contribution. I particularly like that both the author and Dr Edwards are pointing out the most basic flaw that seems to being ignored by almost all reporters, in that they are actually reporting on the success of their brainwashing techniques (small as it is) and there is no objective measure of improvement at all.
They could so easily have included a real control group–they had far more money than they needed for a simple questionnaire study, yet they appear to have made no effort to do a meaningful study at all. It is utterly incomprehensible that we are still arguing about it.
It must seem very puzzling to many readers why the PACE principal investigators should be so eager and went to such lengths to prove in this PACE trial that these two treatments, CBT and GET, should be given to and in some cases enforced on patients.
The answer lies with the PACE principal investigator’s funders – the insurance industry and the UK government’s Department for Work and Pensions (DWP) – who they have had close undisclosed links to since the 1990s. The positive results from CBT and GET were required from the very start to prove that the disease is instead simply psychological rather than neurological and also easily overcome by these two treatments.
The motive is that if these clearly ineffective treatments do not work then the patient can be blamed for not wanting to get better from their so called “false illness beliefs” and insurance or welfare benefits can then be terminated saving billions of dollars. Note that psychological illnesses are excluded or restricted from insurance policies unlike physical disorders.
David Tuller also covers this in his article:
http://www.virology.ws/2015/11/17/trial-by-error-continued-pace-teams-work-for-insurance-companies-not-related-to-pace-really/
I find it deeply worrying the DWP saw fit to part fund the PACE trial. Begs the simple question: Why would they do that?
If the trial results had demonstrated:-
1) That CFS/ME is physiological. The DWP would have then have to provide the same financial support as for other physiological conditions, and consider their back-to-work strategies accordingly.
2) A 50/50 confidence level that CFS/ME is physiological versus psychological. Inconclusive, and many sufferers could have still strongly argued there case to the DWP, perhaps with significant medical backing.
3) That CFS/ME is psychological. The DWP would then have a get-out-of-jail-free-card, getting off with providing minimal financial support, and pushing sufferers to get back into work.
I cannot imagine the DWP having the slightest inclination to help fund PACE if it thought ‘1’ would result, nor if it thought ‘2’ was on the cards (altruism seems very hard to credit). So to me ‘3’ seems the most likely reason the DWP agreed to part-fund this research.
But for me the really worrying bit is that funding comes up-front, before a trial starts, let alone before the results are known. Would the DWP really have agreed to part-fund this trial if they had no inkling of how it would turn out? Would they have really agreed unless they already had a pretty high confidence of how it would turn out? What did motivate the DWP here? And how confident can the rest of us be that the PACE trial was not skewed before it even began?
The PACE trial manual states that the findings of the trial, will apply to the sickest patients, even more so than the people begin studied.
it is hard to understand how/why a study with few objective measurements was accepted?
Q. “However any change in a statistical plan brings an elephant into the room: why did the authors decide to use the continuous scores?”
A. “Because PACE’s “sister” study, the FINE trial, had reported NULL RESULTS at the 70-week endpoint that-is, UNTIL the investigators rescored the data using a continuous scale rather than the bimodal scale used in the original paper.”
http://www.virology.ws/2015/11/09/trial-by-error-continued-why-has-the-pace-studys-sister-trial-been-disappeared-and-forgotten/
… so, yet more massaging of the data to get the results they wanted.
Posting with express permission from Invest in ME. Unfortunately the full article is too long to be posted here..please see this link: http://www.investinme.org/IIME-Newslet-1603-01.htm
The PACE Trial Did Not Go Unchallenged for Five Years
Margaret Williams 28th March 2016
Thank you very much for this important critiscism of the PACE trial!
However, there was important critiscism of the PACE trial, before David Tuller wrote his critical articles in 2015.
Please read: The PACE Trial Did Not Go Unchallenged for Five Years, by Margaret Williams 28th March 2016 http://www.investinme.org/IIME-Newslet-1603-01.htm
In 2010, Prof. Malcolm Hooper (UK) released a 442 page report, called “Magical Medicine: How to make a disease disappear” with strong critiscism of the PACE trial. Please see the references here: http://www.investinme.org/Article400%20Magical%20Medicine.htm
Prof. Hooper’s complaint in 2010 to the Medical Research Council about the PACE trial was basically ignored.
Thanks, Helle, for bringing that to our attention.
I am a patient in the Uk who has had ME for nearly twenty years. Initially I had it mildly – following Graded Exercise Therapy I dramatically worsened to the point where I am now housebound, needing to be in bed for 22 hours a day. My story is not unique – many others report being made disabled by Graded Exercise Therapy – the very thing that the PACE trial supposedly ‘proves’ is the best chance of recovery from ME. Bad science has life-changing consequences for patients. For this reason I am profoundly grateful for you tackling the PACE trial and exposing its flaws. Thank you.
Thank you Tanya for writing to us. We can only hope that there is relief soon for you – and for all those suffering with ME/CFS.
I’m very sorry to hear that, do look at Drmyhill.co.uk.
Her work is remarkable and has helped many; she no longer takes patients but her she generously publishes all her work and suggestions for free. I have improved markedly following her protocol.
Dr. Goldin, Thank you for your thorough analysis of the PACE trial. Using Pubmed Commons, I have linked your post to the PACE recovery article on Pubmed.
Thank you for doing that—and for submitting your insightful comment.
I’d also like to add that outside of the PACE trials, surveys of thousand of patients, across countries and over a decade, consistently show that approximately 50% of patients felt their health worsened with exercise programs. See this link:
http://iacfsme.org/ME-CFS-Primer-Education/Bulletins/BulletinRelatedPages5/Reporting-of-Harms-Associated-with-Graded-Exercise.aspx
When I was asked to sit on an FDA panel in 2013 addressing drug development for ME/CFS, I conducted a survey of 600+ US residents about how various treatments were working for them. 62% cited that formal exercise programs, i.e. those carried out/ prescribed by a health professional, worsened their health.
In any other medical condition, regardless of formal study results, if 50% or more of patients reported that a treatment was causing them harm rather than benefit, that treatment would be subject to intense review. Yet the PACE authors did not acknowledge this any of their published papers. It is extremely foolish of clinicians/ researchers to ignore patients.
The PACE trial did NOT go ‘unchallenged for five years’ In fact, from the time it began, throughout its process and after its publication it was challenged by a good few people, including by me, a research methodologist in the social sciences; Professor Emeritus Malcolm Hooper; and many others. I was one of the first to mount a cohesive critique which I did sustain throughout the trial. I wrote a book in 2012 detailing the flaws in psychogenic explanations that underpin the belief systems that gave rise to the PACE trial and others, and have contributed letters to various journals on the subject. I have submitted key findings, including to the Lancet itself, about the flaws in the PACE trial. Sadly these were ignored and I had a surreal experience at their hands which has made me terrified for the future of ‘science’ frankly. My book is “Authors of our own Misfortune? The Problems with Psychogenic Explanations for Physical Illnesses”, published in 2012. I have also given an annotated bibliography and summary of my work on PACE over the years on a Blog about my complaint against PACE to the Lancet (given here as my website). There are many fundamental methodological problems with the PACE trial which renders it dangerous to patients. I believe in the circumstances the safest measure would be for it to be retracted.
Released: 14th of April,2016.
A new report from the British Centre for Welfare Reform explains how a current scientific controversy relates to the debate surrounding welfare reform and cuts to disability benefits. http://www.centreforwelfarereform.org/news/misleading-mability-cuts/00270.html
“A large and expensive assessment of biopsychosocial interventions, PACE, the only such trial to have received funding from the Department of Work and Pensions (DWP), provides a clear example of the problems which can affect academic research and distort our understanding of important issues. This report explains how problems with the design of this trial, and the presentation of its results, led to seriously misleading claims about patients’ recovery rates.”
Direct link to the report “In the Expectation of Recovery. Misleading medical research underpins disability cuts” by George Faulkner: http://www.centreforwelfarereform.org/uploads/attachment/492/in-the-expectation-of-recovery.pdf
April 15, 2016: Great letter by Professor Malcolm Hooper(UK)to the editor of the Lancet, Dr. Richard Horton, asking for retraction of the PACE trial. http://www.meactionuk.org.uk/Hooper-to-Horton-15-April-2016.htm
“It is to be regretted that The Lancet, once regarded as an eminent medical journal, has aligned itself with these obstructions to the progress of medical understanding [of ME/CFS]and continues to resist calls for retraction of the paper and/or release of the anonymised data for others to study.
It is within your purview to change this and restore the reputation of the journal and medical science in the UK and internationally.”
Thank you Rebecca.
You have managed to add a voice to everything people with ME have been thinking since this PACE Study materialized. For critics to say it was just a study is an understatement. Every one of us have been subjected to CBT & GET at some point since we are diagnosed. I would give anything to have my Mensa IQ and photographic memory back. Instead PACE gave me a stigma making it difficult for me to be treated as human being. And because ME robbed me of the ability to stand up for my rights there isn’t anything I can do to defend myself from the psychological rape of having to carry this stigma for the rest of my life.
The first four paragraphs are verbose, repetitive and poorly written. Editor should advise readers to ignore everything but the first sentence of paragraph one and the last sentence of paragraph four. The rest is a poorly formatted footnote.
Good info. Lucky me I recently found your blog by
chance (stumbleupon). I’ve saved as a favorite for later!